Mitigating Catastrophic Forgetting Using Improved Clustering-Based Episodic Memory
Online Continual Learning (Domain-Incremental, Task-Agnostic) — STRATA-I and STRATA-II
Abstract
Online Continual Learning (OCL) is a subdomain of machine learning in which models must continuously learn from a perpetual data stream without access to past samples. Models using domain incremental learning can adapt to shifting sample distributions, known as new tasks, while retaining accuracy on previously-trained tasks, without needing to know the precise moment when the task switches. However, domain incremental learning models are often susceptible to a loss in accuracy on earlier tasks as they train on subsequent tasks. We propose two new domain-incremental balanced stochastic gradient models with improved clustering-based episodic memory, STochastic gRAdient with Task-Agnosticity (STRATA-I and STRATA-II), and demonstrate strong performance on several benchmark datasets and tasks compared to previous state-of-theart models, including reducing forgetting in at least two cases by over 75%.
Problem
In domain-incremental online continual learning, task identity and task boundaries are not available, while the data distribution shifts over time. Many models forget earlier tasks as training continues.
Previous Work
Prior work has explored task-agnostic clustering-based episodic memory, which attempts to group samples by underlying task structure without access to explicit task labels [1]. Among non-task-agnostic approaches using episodic memory, MEGA-I and MEGA-II are particularly strong methods: they combine gradients from memory and incoming samples by either rotating or balancing them based on relative loss values [2].
- [1] Lamers, Christiaan, René Vidal, Nabil Belbachir, Niki van Stein, Thomas Bäeck, and Paris Giampouras. "Clustering-based domain-incremental learning." In Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 3384-3392. 2023.
- [2] Guo, Yunhui, Mingrui Liu, Tianbao Yang, and Tajana Rosing. "Improved schemes for episodic memory-based lifelong learning." Advances in Neural Information Processing Systems 33 (2020): 1023-1035.
Our Upgrades
- When a cluster is full, remove the sample farthest from the cluster mean (instead of FIFO).
- Integrate this memory into MEGA-style gradient balancing to form STRATA-I and STRATA-II.
Key Results
STRATA-I and STRATA-II generally reduce forgetting compared to baselines across most datasets and task types, with especially strong reductions in class-split settings. Overall accuracy is also competitive and often best.
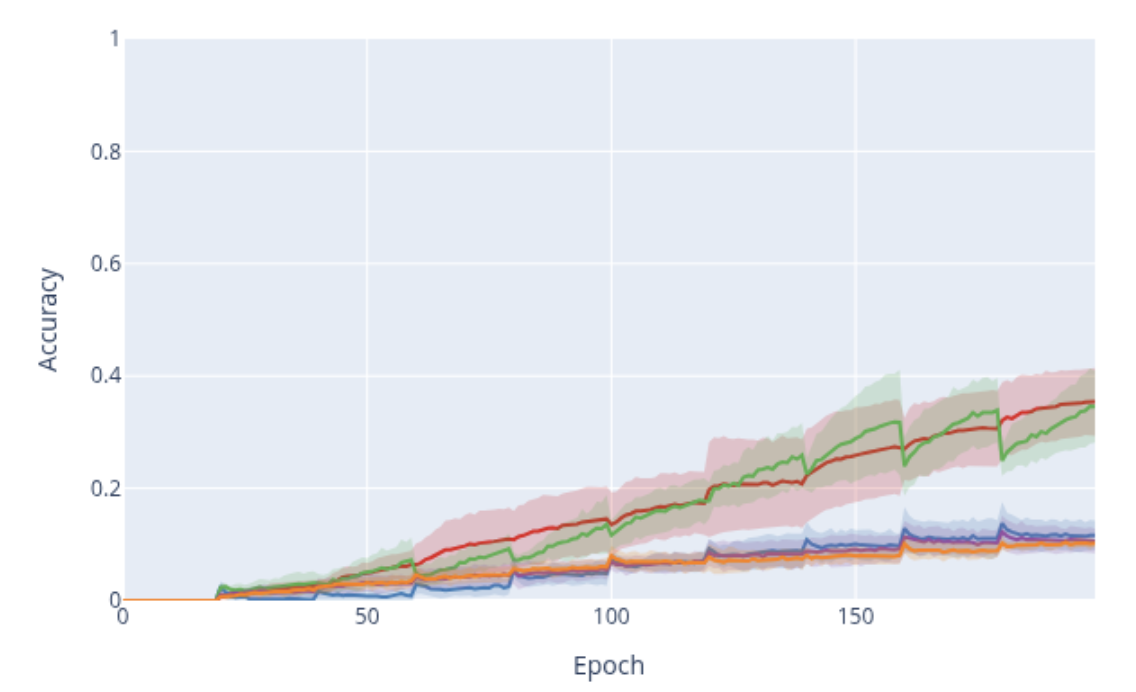

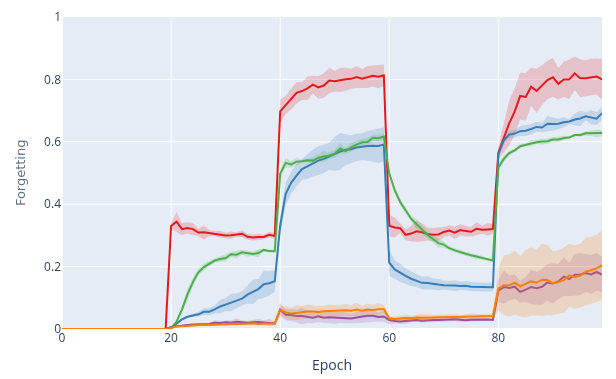
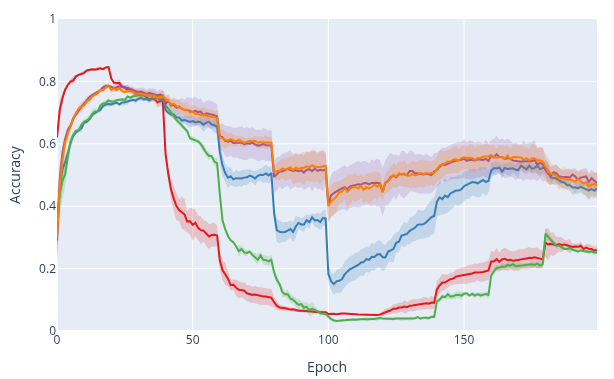
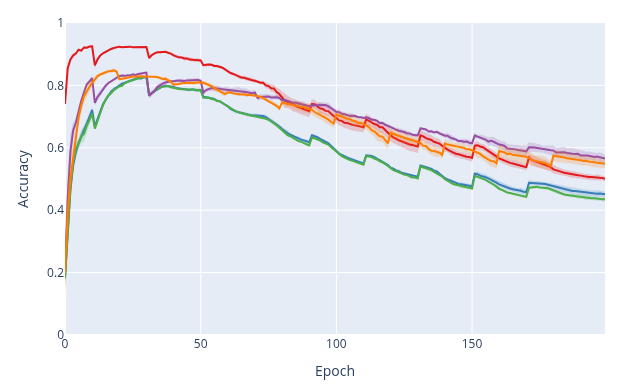
Method summary
Episodic memory update
- Per class label, maintain a pool of clusters with a maximum number of clusters and samples per cluster.
- Assign new samples to the nearest cluster mean (or create a new cluster if capacity allows).
- If a cluster exceeds capacity, remove the sample farthest from the cluster mean (l2 distance), then recompute the mean.
STRATA-I vs STRATA-II
- STRATA-I: loss-weighted mixing of current gradient and reference gradient from episodic memory.
- STRATA-II: rotates the current gradient toward the reference gradient using a loss-balanced angle.
Experimental setup
- Datasets: MNIST, Fashion MNIST, CIFAR-10
- Task types: permutation, rotation, class-split
- Task presentation: sequential tasks (no overlap) and continual/overlapping transitions
- Baselines: TA-A-GEM, Bayesian Gradient Descent (BGD), random add/remove episodic memory